# Fluent-bit Config Reference
# 1. Environmental preparation
- Kubernetes Cluster
- Deployed clickvisual
- Deployed fluent-bit through DaemonSet
Let's briefly introduce the workflow of fluent-bit(Official documents (opens new window)):
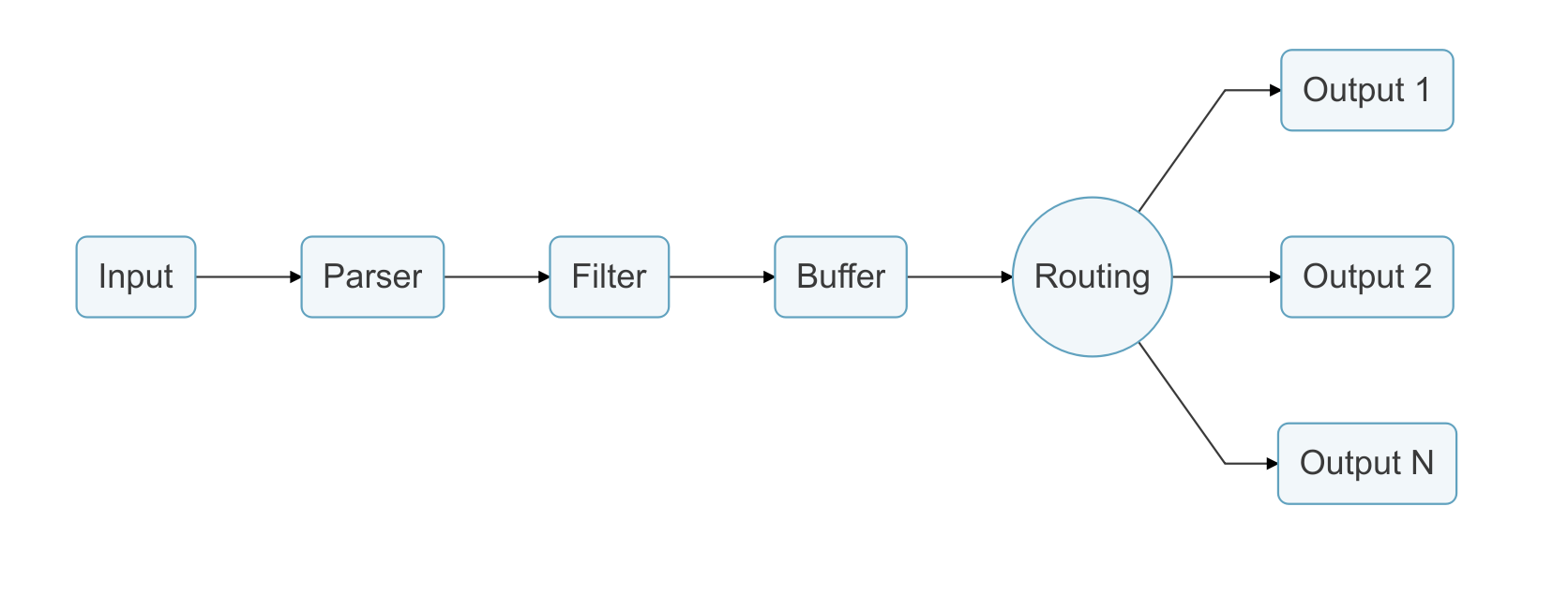
Logs are sent from the data source to the destination through a data pipeline. A data pipeline can be composed of Input, Parser, Filter, Buffer, Routing, Output, etc.
- Input plugin: It is used to extract data from the data source. A data pipeline can contain multiple input plugins.
- Parser plugin: It is responsible for transforming the unstructured data extracted by input plugin into standard structured data. Each input plugin can define its own Parser.
- Filter plugin: Responsible for filtering and modifying formatted data. A data pipeline can contain multiple filters, and the execution order of multiple filters is consistent with that in the configuration file.
- Buffer plugin: The user caches the data processed by the filter. By default, the buffer caches the data of the input plugin in memory until the route is delivered to the output plugin.
- Routing plugin: Route the cached data in the buffer plugin to different output plugins.
- Output plugin: It is responsible for sending data to different destinations. A data pipeline can contain multiple output plugins.
Suppose you deploy Fluent-bit in the DaemonSet mode, and your goal is to collect the Nginx Ingress logs and business standard output logs of the kubernetes cluster. You can refer to the following example to configure your Fluent-bit.
You can config Fluent-bit by the visual config panel at ClickVisual.The detail operation is: Click top nav bar,access Config.Then select Fluent-bit Cluster / Namespace / ConfigMap on the page.If the cluster data has been not entered,refer toSetting (opens new window)
The following figure shows how to edit fluent-bit-config of the kube-system namespace in the xxx-dev cluster.
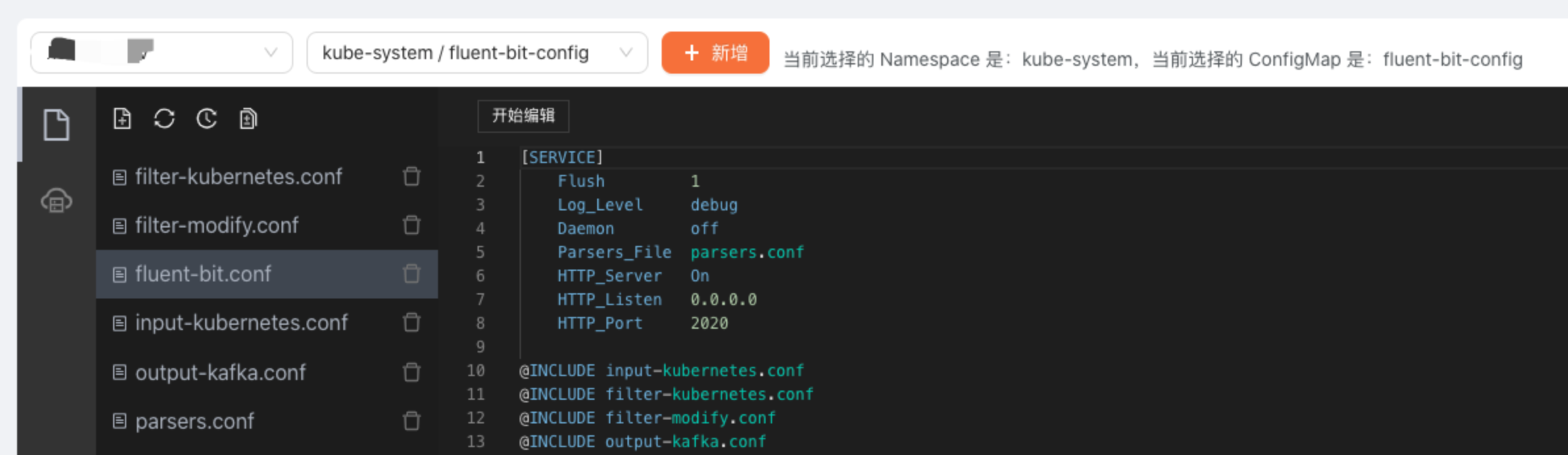
Click『Start editing』button on the top of edit area to edit config file.When finish,click『Save』Button,then click  button on the left and select specified config file and version. At last click『Publish』button to synchronize the configuration to ConfigMap.It will works by restart fluent-bit.
button on the left and select specified config file and version. At last click『Publish』button to synchronize the configuration to ConfigMap.It will works by restart fluent-bit.
# 2. Config description
When you use DaemonSet to deploy Fluent-bit and you hope to collect Nginx Ingress logs and business standard output logs in Kubernetes Cluster.Then you can refer to the following example to config your Fluent-bit.
# 2.1. fluent-bit.conf
flient-bit.conf Storage tier configuration global environment configuration
[SERVICE]
# The interval of flushing output in seconds
Flush 1
# Log level: error/warning/info/debug/trace
Log_Level info
# Run as daemon or not
Daemon off
# Specify the configuration file for parser
Parsers_File parsers.conf
# Start HTTP server or not
HTTP_Server On
# HTTP Server listen Host
HTTP_Listen 0.0.0.0
# HTTP Server listen Port
HTTP_Port 2020
# 引用 input-kubernetes.conf
@INCLUDE input-kubernetes.conf
# 引用 filter-kubernetes.conf
@INCLUDE filter-kubernetes.conf
# 引用 filter-modify.conf
@INCLUDE filter-modify.conf
# 引用 output-kafka.conf
@INCLUDE output-kafka.conf
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 2.2. parse.conf
parse.conf config Parser for input plugin.
[PARSER]
Name nginx
Format regex
Regex ^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]
Name json
Format json
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]
Name docker
Format json
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L
Time_Keep On
# Similar to the effect Merge_Log=On at filter stage, the JSON content of the log field is parsed, but cannot be extracted to the root level
#Decode_Field_As escaped_utf8 kubernetes do_next
#Decode_Field_As json kubernetes
[PARSER]
# http://rubular.com/r/tjUt3Awgg4
Name cri
Format regex
Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<message>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
[PARSER]
Name syslog
Format regex
Regex ^\<(?<pri>[0-9]+)\>(?<time>[^ ]* {1,2}[^ ]* [^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?(?:[^\:]*\:)? *(?<message>.*)$
Time_Key time
Time_Format %b %d %H:%M:%S
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 2.3. input-kubernetes.conf
input-kubernetes.conf Configure the specific logs collected by fluent-bit (Nginx Ingress, business standard output logs, node system logs, etc.) and the detail parameters.
# Collect ingress access log, access and error logs are not distinguished at present.Later, it is separated through the filter plugin.
[INPUT]
# use tail plugin
Name tail
# Tag identify the data source, which is used to select data in the subsequent process filter and output
Tag ingress.*
# Nginx Ingress log collect path
Path /var/log/containers/nginx-ingress-controller*.log
# use docker Parser
Parser docker
# Specify the monitored file name and the database for offsets persistence
DB /var/log/flb_ingress.db
# Specify the maximum memory used by the tail plugin. If the limit is reached, the plugin will stop collecting and recover after refreshing the data.
Mem_Buf_Limit 15MB
# Set the initial buffer size to read files data.
Buffer_Chunk_Size 32k
# Set the limit of the buffer size per monitored file.
Buffer_Max_Size 64k
# Skip the row when length greater than Buffer_Max_Size. If Skip_Long_Lines is Off, the collection will be stopped when encounter the row above.
Skip_Long_Lines On
# The interval of refreshing the list of watched files in seconds.
Refresh_Interval 10
# If the acquisition file has no database offset record, it is read from the header of the file. When the log file is large, it will lead to the increase of fluent memory usage and oomkill
#Read_from_Head On
# Collect ingress error log, access and error logs are not distinguished at present.Later, it is separated through the filter plugin.
[INPUT]
Name tail
Tag ingress_stderr.*
Path /var/log/containers/nginx-ingress-controller*.log
Parser docker
DB /var/log/flb_ingress_stderr.db
Mem_Buf_Limit 15MB
Buffer_Chunk_Size 32k
Buffer_Max_Size 64k
Skip_Long_Lines On
Refresh_Interval 10
#Read_from_Head On
# Collect stdout、stderr logs of containers
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*.log
Exclude_path *fluent-bit-*,*mongo-*,*minio-*,*mysql-*
Parser docker
DB /var/log/flb_kube.db
Mem_Buf_Limit 15MB
Buffer_Chunk_Size 1MB
Buffer_Max_Size 5MB
Skip_Long_Lines On
Refresh_Interval 10
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 2.4. filter-kubernetes.conf
filter-kubernetes. Conf mainly adds kubernetes metadata to the collected logs in the kubernetes environment, such as kubernetes_host、kubernetes_namespace_name、kubernetes_container_name、kubernetes_pod_name etc.
[FILTER]
# use kubernetes filter
Name kubernetes
# Match ingress* input plugin corresponding to this tag
Match ingress.*
# API Server end-point
Kube_URL https://kubernetes.default.svc:443
# CA certificate file
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
# Token file
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
# When the source log comes from the tail plugin, this configuration is used to specify the prefix value used by the tail plugin
Kube_Tag_Prefix ingress.var.log.containers.
# When enabled,it parses the JSON content of the log field, extract it to the root level, and attach it to the field specified by Merge_Log_Key.
Merge_Log Off
# Whether to keep the original log field after merging the log field
Keep_Log Off
# Allow Kubernetes Pods to suggest a pre-defined Parser
K8S-Logging.Parser Off
# Allow Kubernetes Pods to exclude their logs from the log processor
K8S-Logging.Exclude Off
# Whether to include Kubernetes resource tag information in additional metadata
Labels Off
# Whether to include Kubernetes resource information in additional metadata
Annotations Off
[FILTER]
Name kubernetes
Match ingress_stderr.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix ingress_stderr.var.log.containers.
Merge_Log Off
Keep_Log Off
K8S-Logging.Parser Off
K8S-Logging.Exclude Off
Labels Off
Annotations Off
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix kube.var.log.containers.
Merge_Log Off
Keep_Log Off
K8S-Logging.Parser Off
K8S-Logging.Exclude Off
Labels Off
Annotations Off
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 2.5. filter-modify.conf
filter-modify.conf mainly used to modify log fields.
#This filter used to add 'kubernetes_' prefix to the fields of logs containing pod_name.
[FILTER]
Name nest
Match *
Wildcard pod_name
Operation lift
Nested_under kubernetes
Add_prefix kubernetes_
# Adjust some Kubernetes metadata field names and append some additional fields
[FILTER]
# use modify filter
Name modify
# match all INPUT
Match *
# rename stream to _source_
Rename stream _source_
# rename log to _log_
Rename log _log_
# rename kubernetes_host to _node_name_
Rename kubernetes_host _node_name_
# rename kubernetes_namespace_name to _namespace_
Rename kubernetes_namespace_name _namespace_
# rename kubernetes_container_name to _container_name_
Rename kubernetes_container_name _container_name_
# rename kubernetes_pod_name to _pod_name_
Rename kubernetes_pod_name _pod_name_
# remove all matching kubernetes_ Fields
Remove_wildcard kubernetes_
# add _cluster_ config,its value is the environment variable CLUSTER_NAME configured in fluent-bit daemonset
Add _cluster_ ${CLUSTER_NAME}
# add _log_agent_ config,its value is the environment variable HOSTNAME configured in fluent-bit daemonset
Add _log_agent_ ${HOSTNAME}
# add _node_ip_ config,its value is the environment variable NODE_IP configured in fluent-bit daemonset
Add _node_ip_ ${NODE_IP}
#Filter ingress.* Input to exclude the original logs containing "stderr" to ensure that all logs are access logs.
[FILTER]
Name grep
Match ingress.*
Exclude _source_ ^stderr$
#Filter ingress_stderr.* Input to exclude the original logs containing "stdout" to ensure that all logs are stderr.
[FILTER]
Name grep
Match ingress_stderr.*
Exclude _source_ ^stdout$
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 2.6. output-kafka.conf
output-kafka.conf mainly defines how logs are pushed to Kafka.
# This kafka output plugin will push Nginx Ingress access log to Kafka
[OUTPUT]
# use kafka plugin
Name kafka
# match Nginx access logs
Match ingress.*
# set Kafka Brokers address
Brokers ${KAFKA_BROKERS}
# set Kafka topic,multiple topics are separated by ','
Topics ingress-stdout-logs-${CLUSTER_NAME}
# set Timestamp_Key to _time_,the original default value is @timestamp
Timestamp_Key _time_
# set timestamp format
Timestamp_Format iso8601
# setting to false means that the number of retries is not limited
Retry_Limit false
# when Kafka ends an idle connection,hide "Receive failed: Disconnected" errors
rdkafka.log.connection.close false
# The maximum total message capacity in the Kafka producer queue is set to 10MB here,producer buffer is not included in. http://fluentbit.io/documentation/0.12/configuration/memory_usage.html#estimating
rdkafka.queue.buffering.max.kbytes 10240
#The Kafka producer will not send the next message until the leader broker has successfully received the data and has been confirmed.
rdkafka.request.required.acks 1
[OUTPUT]
Name kafka
Match ingress_stderr.*
Brokers ${KAFKA_BROKERS}
Topics ingress-stderr-logs-${CLUSTER_NAME}
Timestamp_Key _time_
Timestamp_Format iso8601
Retry_Limit false
rdkafka.log.connection.close false
rdkafka.queue.buffering.max.kbytes 10240
rdkafka.request.required.acks 1
[OUTPUT]
Name kafka
Match kube.*
Brokers ${KAFKA_BROKERS}
Topics app-stdout-logs-${CLUSTER_NAME}
Timestamp_Key _time_
Timestamp_Format iso8601
Retry_Limit false
rdkafka.log.connection.close false
rdkafka.queue.buffering.max.kbytes 10240
rdkafka.request.required.acks 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46